LLMs Are for Builders
“Coffee is for closers” is a great line because the coffee is not really coffee.
It is permission. Status. Access to the machine in the corner. The closer is the person who turns a lead into revenue, so the closer gets the ritual object. Everyone else gets told to get back to work.
The builder version is the same joke with a different prize.
Closers get to have the coffee.
Builders get to have the LLM.
 Vic Vijayakumar put the axis cleanly: build vs code.
Vic Vijayakumar put the axis cleanly: build vs code.
That is the distinction I keep coming back to. This is not about whether coding is good or bad. I like code. I like editors, REPLs, weird little shell scripts, and spending too long shaving down a function until it has the right shape.
But code is the medium. Building is the point.
The people getting the most out of LLMs are not necessarily the people who want to type fewer characters. They are the people staring at the awkward customer workflow, the tool that almost fits, the integration that needs one more escape hatch before it stops feeling hacky, and thinking: fine, let’s make the actual thing.
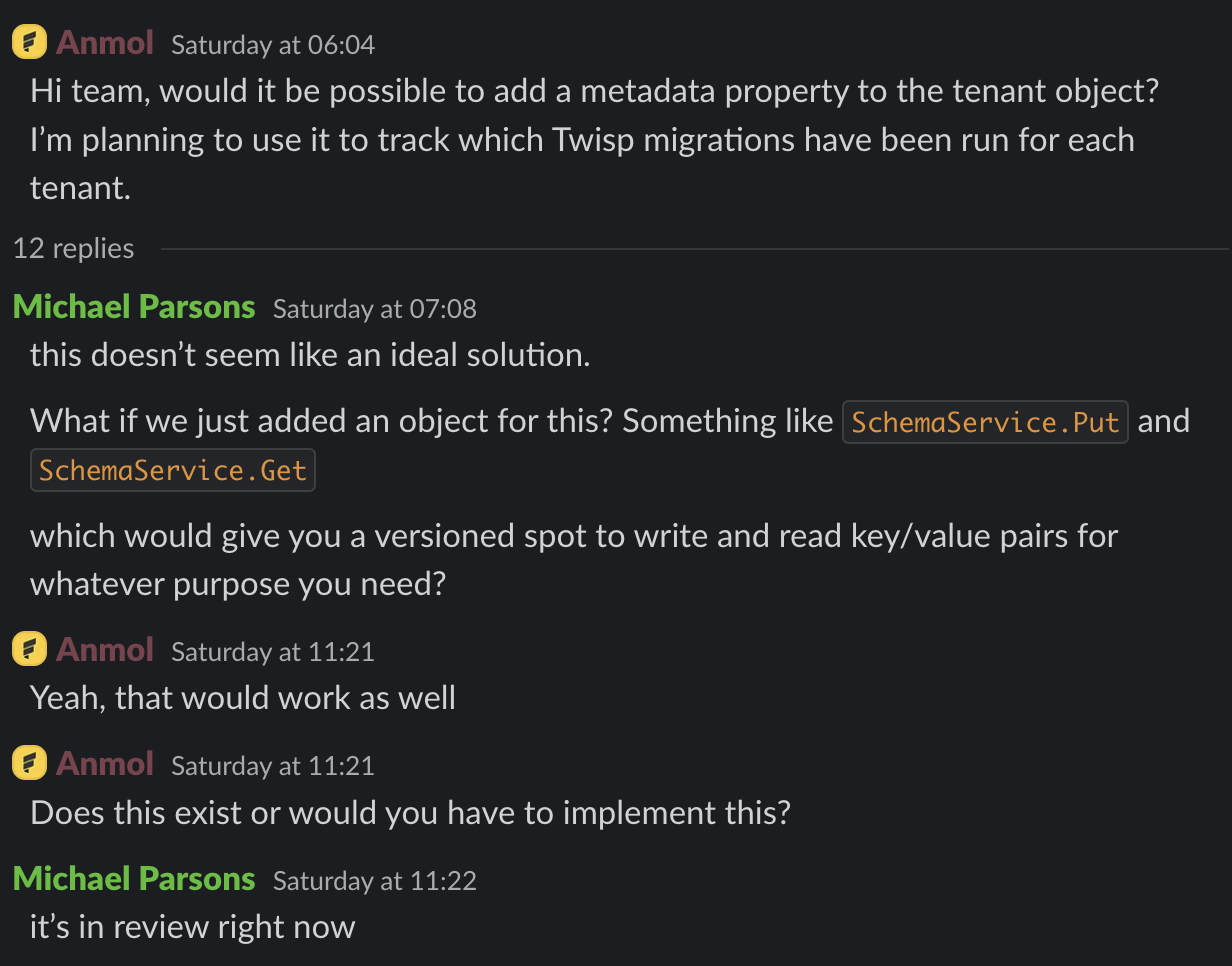 A Saturday itch becoming a product surface.
A Saturday itch becoming a product surface.
That screenshot is the whole thing in miniature. A customer has a practical need: track which Twisp migrations have been run for each tenant. He’s building and shipping, sometimes you reach for the kludge. Today it is migrations. Tomorrow it is integration checkpoints, rollout flags, customer-specific workflow state, and five other things that should be versioned, queryable, and boring.
The better answer was sitting one abstraction higher: what if the ledger had a small, transactional, versioned key/value surface? Something generalized enough to handle any structured application state that needs to live next to ledger data.
That turned into a KV ledger.
The old version of me might have put that idea on a list. Not because it was bad, but because it had too much shape. A real version needed API design, storage behavior, docs, tests, GraphQL examples, idempotency semantics, update semantics, and enough polish that a customer would not feel like they were holding a prototype with sharp edges.
Now that is a Saturday-sized problem.
Not a trivial problem. Not “the model did it all while I was making pancakes.” But small enough that the ambition math changes. I can look at a customer request and ask, “What is the version of this that would actually make the product better?” instead of “What is the smallest patch that gets us out of the conversation?”
That is a very different operating mode.
The Ambition Budget Changed
Every engineer has an ambition budget. It is the invisible account you draw from when you decide whether to polish a tool, write the better doc, build the reusable thing, or finally fix the editor annoyance you have been stepping around for six months.
Before these coding tools got good, the budget was tight. You had to be careful with it. A customer wanted one little field? Fine, add the field. Your Emacs package worked through vterm, but the experience was a little clunky? Fine, live with it. The docs were accurate but not friendly? Fine, ship them. There were always bigger fires.
LLMs change the budget because they compress the boring middle.
They do not remove taste. They do not remove judgment. They do not tell you what should exist. But once you can describe the shape of the thing clearly enough, they can chew through a shocking amount of implementation, wiring, documentation, and test scaffolding.
That makes the better version cheaper to attempt.
If you mostly like to code, the LLM looks like autocomplete with opinions. Useful, sometimes annoying, often impressive, occasionally wrong in ways that make you roll your eyes (or if I’m being completely honest, toss the laptop across the room).
If you like to build, it looks more like leverage. It is the extra set of hands that lets you try the bigger version of the idea before the idea goes cold.
I did not like running claude-code-ide through vterm, so I added ghostel support. That is exactly the sort of itch I used to ignore. The tool worked. I could cope. The delta between “annoying” and “nice” was not worth an evening.
Except now it often is.
The point is not that every itch deserves a package, a PR, or a product surface. The point is that the old filter is obsolete. A lot of ideas were not rejected because they were wrong. They were rejected because the implementation cost was too high for the amount of certainty you had.
When the cost drops, some of those ideas deserve to be reconsidered.
Customers Feel the Difference
There is a temptation to use LLMs to move faster in the most literal way: same scope, less time. That is useful, but it is the least interesting version of the story.
The better version is: same time, better artifact.
When a customer asks for something, you can hand them the narrow fix. Sometimes that is the right call. But often the customer is pointing at a symptom. They are telling you where the product model is thin.
“Can we put metadata on tenants?” might really mean:
- We need application state that is consistent with ledger state.
- We need a place for operational checkpoints.
- We need version history when that state changes.
- We need this without making every object in the system grow a random
metadatafield.
That is a better problem. It is also a harder one. LLMs make it more reasonable to chase the harder problem far enough to see if it is real.
This matters because customers can feel when you gave them a patch instead of a product. They can feel when an API is a special case. They can feel when the docs were written after the fact. They can feel when the example is just barely enough to pass the support thread.
They can also feel when the thing snaps into place.
Better Artifacts Make Better Models
The other lesson is that the model is only as fast as the artifacts you hand it.
I do not mean “prompt engineering” in the mystical sense. I mean the plain engineering version:
- Give it the screenshot.
- Give it the docs link.
- Give it the failing test.
- Give it the shape of the API you want.
- Give it examples of how the rest of the codebase does similar work.
- Give it acceptance criteria that would make you comfortable shipping.
The better your artifacts, the less the model has to invent. The less it invents, the more of its energy goes into useful work.
This is why I think builders have the edge. Builders already know how to turn fog into artifacts. We write the issue, make the diagram, cut the reproduction, sketch the API, collect the logs, write the test, and explain the constraint. Those were always valuable skills. Now they are force multipliers.
If you want better output from an LLM, do not just ask harder. Bring better material.
Build, Baby, Build
So that is my pitch.
Dust off the old ideas you thought were too ambitious. Not all of them. Some were bad for a reason. But find the ones you quietly believed in and abandoned because the hill looked too steep.
Level up the artifacts you give people. A good issue, a good doc, a good screenshot, a good test, a good example repository: these are not chores around the work. They are part of the work. They help humans move faster, and they help models move faster too.
And then build.
Build the customer-facing version instead of the hack.
Build the tool support that makes your own loop nicer.
Build the doc that would have saved you the support call.
Build the tiny product surface that turns a one-off request into a durable capability.
Closers get to have the coffee.
Builders get to have the LLM.